
Drifting Efficiently Through the Stratosphere Using Deep Reinforcement Learning
How Loon and Google AI achieved the world’s first deployment of reinforcement learning in a production aerospace system
Editor’s note: This blog was originally published by the Loon team on December 2, 2020. In 2021, Loon's journey came to an end. The Loon team have shared their flight data and technical, operational and scientific insights in The Loon Collection to support the next generation of stratospheric innovation. Thank you to everyone who supported the Loon team along the way.
Driving a superpressure balloon through the stratosphere has only two simple options: go up or go down. Nonetheless, navigating that balloon skillfully is deceptively complex. Navigation is particularly well suited for automation for various reasons¹, and on Loon we have always heavily leveraged automated systems as we strive to efficiently steer our balloons to people and places that need connectivity.
Because balloons follow the prevailing winds, in a very real way the best we can hope to do is drift efficiently through the stratosphere. Even with conventional methods that reflexively follow specific, bounded algorithms, maneuvers and flight paths emerge that are interesting and, sometimes, even beautiful.
When we posted about our 1 million hours of flight and interesting emergent navigation behaviors, the topic of what is AI was at the front of my mind because, at that time, we had just launched the maiden voyage of our deep reinforcement learning-based flight control system.
In our ongoing efforts to improve Loon’s navigation system for our stratospheric connectivity mission, a small group of colleagues at Loon and Google AI had been working to develop a more powerful navigation system that leverages deep reinforcement learning (RL), which is a type of machine learning technique that enables an agent to learn by trial and error in an interactive environment using feedback from its own actions and experiences. This contrasts against the conventional approach of the automated system following fixed procedures artisanally crafted by engineers.
While the promise of RL for Loon was always large, when we first began exploring this technology it was not always clear that deep RL was practical or viable for high altitude platforms drifting through the stratosphere autonomously for long durations². It turns out that RL is practical for a fleet of stratospheric balloons. These days, Loon’s navigation system’s most complex task is solved by an algorithm that is learned by a computer experimenting with balloon navigation in simulation.
As far as we know, this is the world’s first deployment of reinforcement learning in a production aerospace system. Today we are honored to share the technical details of how we achieved this groundbreaking result in Nature, and in this post discuss why RL is so important for Loon and our mission to connect people everywhere.
Navigating balloons is getting complex
Navigating balloons through the stratosphere has always been hard. As outlined in the paper, the system must contend with time-varying winds partial visibility of the wind field surrounding the balloon³; complicated system models and constraints, such as not always having enough power for the ideal maneuver; and frequent decision opportunities over a long planning horizon⁴. Even by dramatically simplifying the problem (read as: trading navigation performance for a simpler and more computationally efficient algorithms) in our conventional navigation system⁵, it remains very complicated. Pushing for greater progress and efficiency within the conventional system had already reached levels of complexity that, frankly, made our collective heads hurt.
To add to this headache-inducing problem, our challenge is not just to solve the same task better (although that is important). Additional challenges when considering the holistic connectivity mission — such as low level coordination of a constellation of flight systems, navigating new high altitude platforms with enhanced capabilities, and adapting current tactics to handle new types of navigation goals needed by Loon’s diversifying product lines — add complexity to the mission.
Reinforcement learning is an intriguing technology to address these challenges for Loon. It holds the promise to not only allow us to steer balloons better than the human-designed algorithms we use now, but also to ramp up on these new challenges quickly to enable our navigation system to manage new aircraft and different uses of the Loon fleet. While RL has been around for a long time, the field has experienced a renaissance due to the infusion of high capacity function approximators in the form of deep neural networks.
Sleepwalking into the RL World
A few years ago we kicked off the Loon navigation deep RL project, codenamed Project Sleepwalk, as a stealthy collaboration between Loon and the Google AI team in Montréal. Leveraging some of my friends and colleagues from back in the day, we decided to get the band together again to try something a bit Looney. Not only does Google AI house some of the most brilliant people on the planet but also their team has the latitude to work across Alphabet and, like us, they like to do crazy things. The collaboration was a perfect fit.
To prove out the viability of RL for navigating stratospheric balloons, our first goal was to show we could machine learn a drop-in replacement for our then-current navigation controllers. To be frank, we wanted to confirm that by using RL a machine could build a navigation system equal to what we ourselves had built. At a high level, our approach was to build a new distributed training system that leveraged Loon’s proprietary simulation of balloons in the stratosphere and a learner that uses distributional Q-learning⁶ to make sense of tens of millions of simulated hours of flight. The learned deep neural network that specifies the flight controls is wrapped with an appropriate safety assurance layer to ensure the agent is always driving safely.
Across our simulation benchmark we were able to not only replicate but dramatically improve our navigation system by utilizing RL. It was time to take flight.
Sleepwalking into the Real World (Machines: 1 / Sal: 0)
Despite the excitement around reinforcement learning these days, deploying it at scale for persistent operation in a production aerospace system like Loon has never been achieved before. Despite the success of the new approach in our simulations, a common challenge for RL systems is transitioning from simulation to the real system due to discrepancies between simulation and the real world⁷. The goal of our first flight demonstration was to assess whether this would be a showstopper.
In July of 2019, we flew a Loon balloon using this machine learned controller, codenamed cannelloni7⁸, in the stratosphere above Peru. As a control, we flew a nearby balloon using the older generation navigation system using an algorithm called StationSeeker. Both systems were able to operate completely autonomously throughout the test without any human intervention.
To test the effectiveness of RL vs. StationSeeker, we measured the proximity over time of the two respective balloons to one of Loon’s Romer boxes, which is a device we use to measure LTE service levels in the field. In some sense it was the machine — which spent a few weeks building its controller — against me — who, along with many others, had spent many years carefully fine-tuning our conventional controller based on a decade of experience working with Loon balloons. We were nervous…and hoping to lose.
Beyond just passing a sanity check to show effective navigation in the real (not simulated) stratosphere, cannelloni7 outperformed the conventional system, mitigating the drift of its balloon to consistently keep it closer to the Romer box throughout the entire test. Machine 1, Sal 0. You can see the results in the graph below.
Even more interesting were the subjective things we observed. While one might expect a pure machine-learned system to be ‘rougher’ than the hand designed system, we observed the opposite. Below on the left is a fragment of the StationSeeker trajectory. Contrasting against the Sleepwalk trajectory for the same period of time on the right, you can see a much smoother flight path. To come full circle, it’s almost more akin to what you might expect from human control.
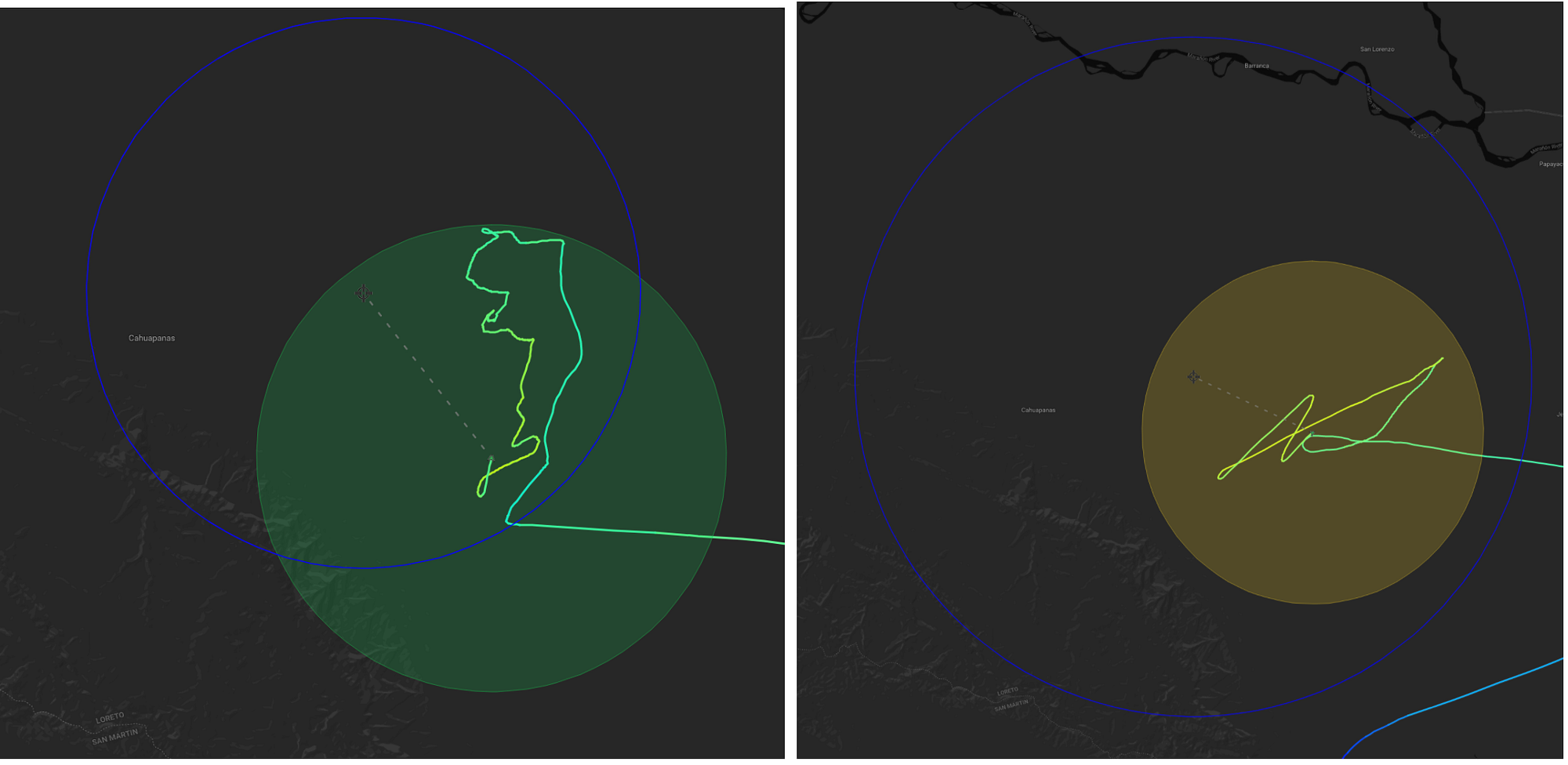
I was watching the test with my Loon colleague, Sameera Ponda. As two people have long stared at balloons drifting through the stratosphere⁹ as we worked on Loon’s navigation system, we were amazed by some of the elegant behaviors we observed from this early RL test. Seeing the system had learned to smoothly tack through a highly localized wind pattern made it clear to us that the RL worked.
A highly localized tacking pattern that resulted from the RL controller.
39 days above the Pacific
We next set out to do a more systematic and comprehensive test¹⁰. We deployed the latest revision of the new learned controllers, codenamed perciatelli44¹¹, at an equatorial location in the stratosphere over the Pacific Ocean where the conventional navigation system was known to perform superbly. The experiment parameters were similar to the first test we ran, with the objective being to remain within 50km of one defined location. The test took place over 39 days, with the RL controller navigating a group of balloons¹² for a total of nearly 3,000 flight hours. The results were excellent.
Overall, the RL system kept balloons in range of the desired location more often while using less power. Obviously, the more closely Loon can remain to a defined location the better as it allows more stable service to people there. Power usage, however, is almost as important. The Loon system is solar-powered and collected energy is a precious commodity. Not only does it power navigation, but it also powers the communications equipment along for and the purpose of the ride. Using less power to steer the balloon means more power is available to connect people to the Internet, information, and other people.
We noticed some very interesting patterns. It was a tortoise and hare situation, with StationKeeper going right for the prize, and perciatelli44 taking a slower, more steady approach. As in the fable, the differences reflected two fundamentally different approaches to achieving the objective. StationSeeker came out of the gate strong, attempting to approach the target location more quickly, often flying by and needing to reverse itself. Interestingly, this is the exact scenario that creates the need to fly the figure 8 pattern we’ve come to know so well.
By contrast, perciatelli44 didn’t attempt to close on the target location as often or as fast, instead focusing more on simply remaining within the target area and stationkeeping as passively as possible. This used far less power, which could then be leveraged in other situations, such as when needing to conduct more significant maneuvers once drifting out of the range entirely.
RL in Production
After confirming performance, we set out to launch the learned controller into Loon’s normal operations. It is an engineering constant that there is typically a huge amount of work transitioning from doing something once to doing it all the time in production. In this rare case, the transition happened quickly and smoothly, with performance improvements on almost every axis.
We find the RL is a great fit for planning and control in real world production systems. While there is often a trade between doing more computation (evaluating alternative action sequences) to plan higher quality decisions and using a simplified model (like a linearized controller) to fit within a smaller computation envelope, RL shifts much of the expensive computation to agent training. This means most of the computational heavy lifting occurs before the flight begins. Throughout the flight our fleet control system only needs to run a “cheap” function, a forward pass through a deep neural network, minute by minute as the balloon drifts through the stratosphere. At the top of the post we discussed efficient movement of the balloon, but the production datacenter workload of this planning system gives a second meaning to the phrase drifting efficiently.
The complex, high-quality behaviors from a simple computational task in the real-time critical path for our navigation system opens new possibilities for solving for complex choreographies of a fleet of balloons that were not previously practical.
Is this balloon AI?
To ape Neil Armstrong, this seemingly simple small step for RL-based balloon flight is a giant leap for Loon. The key difference in approach is that instead of engineers building a specific navigation machine that is really good at steering balloons through the stratosphere, we’re instead (with RL) building the machine that can leverage our computational resources to build the navigation machines that were originally designed by engineers like me. Beyond surpassing the quality of what an engineer can create, this approach allows us to scale to more complicated and numerous tasks than can be done by a small group of people using conventional approaches on conventional timescales. Both quality and scale are required to use high altitude platforms to bring connectivity to more of the billions of under-connected people.
The Loon and Google AI teams hope that beyond Loon, our work on stratospheric navigation can serve as a proof point that RL can be useful to control complicated, real world systems for fundamentally continual and dynamic activity¹³. We think the Loon stationkeeping task highlights aspects of RL that are important open research problems for the community to tackle. On Loon, we will continue to work together with the Google AI Montreal RL team led by my colleague, Marc Bellemare, to improve not only navigation for stratospheric balloons but also help influence how the field of RL evolves to be used for more and more systems like Loon.
In my last post about Loon’s navigation system, I asked the question of whether we were dealing with AI. My answer was uncertain. This time my answer is even more nuanced. While there is no chance that a super-pressure balloon drifting efficiently through the stratosphere will become sentient, we have transitioned from designing its navigation system ourselves to having computers construct it in a data-driven manner. Even if it’s not the beginning of an Asimov novel, it’s a good story and maybe something worth calling AI.
To read the technical details of this work please see our paper in Nature.
---
¹ Balloon navigation requires minute-to-minute attention to detail despite having to watch a slow moving balloon (the stratospheric equivalent of giving intense attention to watching paint dry), continuous assimilation of large amounts of data, and a long planning horizon. These factors make the problem suited to robot, rather than human, navigators.
² Our flight duration record is 312 days, and typically our balloons remain aloft for hundreds of days.
³ We only observe the winds directly at the balloon’s position and in its wake. Forecasts from numerical weather models, while marvels of science and engineering, are not always accurate.
⁴ If we were to evaluate every possible decision sequence we’d need to check something like 3960 different alternatives, without beginning to take into account that there would be uncertainty about the outcomes we do check because we do not have perfect knowledge of the winds. Needless to say, even with aggressive pruning and heuristics helping prioritize the list out decision sequences to check we end up with suboptimal solutions if we treat this as a search problem.
⁵ Loon’s conventional navigation system is a fusion of machine learning techniques like Gaussian processes and conventional control theory, and over the course of many years we have utilized experts to construct control rules that are extremely effective.
⁶ Q-learning is an algorithm that decides what action to take by creating a representation of the goodness of each action in the particular situation the agent is considering (the Q-function) which is learned through experience. Distributional Q-learning is a variant developed by my colleague Marc Bellemare and his collaborators Will Dabney and Remi Munos while at Deepmind that considers a distribution (in the probability sense) of outcomes rather than the expected outcome.
⁷ This challenge is so well known that it carries a specific name: the sim2real gap.
⁸ Due to a strange inside joke between myself and my colleague Jun Gong, all major flight controller releases from the RL system have been named after a pasta.
⁹ Probably not something to write home about.
¹⁰ One game can be random, but over the course of a full season the best players and teams stand out.
¹¹ Again with the pasta.
¹² One of those aircraft, coincidentally, was our record breaking 312 day flight system which can be seen in learned controller flight path #16 in the appendix of the Nature paper.
¹³ RL is used on many physical systems, but not often for long durations of time and in situations where it is hard to press the reset button.